Solve this in python.
QUESTION2: Solve the initial value problem: \( d y / d x=2 x, y(0)=2 \).
Answers
To solve the initial value problem \(dy/dx = 2x\) with the initial condition y(0)=2 in Python, we can use an appropriate numerical method, such as Euler's method or the built-in function odeint from the scipy.integrate module.
Here's an example code snippet in Python that solves the given initial value problem using Euler's method:
import numpy as np
import matplotlib.pyplot as plt
def f(x, y):
return 2*x
def euler_method(f, x0, y0, h, num_steps):
x = np.zeros(num_steps+1)
y = np.zeros(num_steps+1)
x[0] = x0
y[0] = y0
for i in range(num_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
x0 = 0
y0 = 2
h = 0.1
num_steps = 10
x, y = euler_method(f, x0, y0, h, num_steps)
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Solution of dy/dx = 2x')
plt.show()
In this code, we define the function f(x, y) that represents the right-hand side of the differential equation. Then, we implement the Euler's method in the euler_method function, which takes the function f, the initial values x0 and y0, the step size h, and the number of steps num_steps as inputs. The method iteratively calculates the values of x and y using the Euler's method formula. Finally, we plot the solution using matplotlib.pyplot. Running the code will generate a plot showing the solution of the initial value problem dy/dx = 2x with y(0)=2 over the specified range of x-values.
Learn more about Euler's method here:
https://brainly.com/question/33227556
#SPJ11
Related Questions
Area please help I’m desperate

Answers
The area of triangle given in the given image is 180 \(m^2\) as per the given data.
What is area of an triangle?To calculate the area of a triangle, you must first determine the length of the base and the height of the triangle.
The base can be any of the triangle's sides, and the height is the perpendicular distance between the base and the opposite vertex.
The formula for calculating the area of a triangle is A = (1/2) x b x h, where A is the area of the triangle, b is the length of the triangle's base, and h is the height of the triangle.
We know that,
Area = 1/2 x b x h
Here, it is given that:
Base = 30m
Height = 12m
So,
Area = 1/2 x 30 x 12
Area = 180\(m^2\)
Thus, the answer is 180\(m^2\).
For more details regarding triangle, visit:
https://brainly.com/question/2773823
#SPJ7
This is part of a city map.
City map with First Street and Second Street as two lines equal distance apart that never meet. Main Street is intersecting Arch, First, Second, and Elm. Elm Street is intersecting Main and First Street.
Which streets are parallel to each other?
A.
First Street and Second Street
B.
First Street and Arch Street
C.
None of the streets are parallel to one another.
D.
Elm Street and Main Street

Answers
helppppppppppppppppppppp

Answers
Answer:
C. 2, 1
Step-by-step explanation:
pls help asap if you can!!!!

Answers
The statement that proves that angle XWY is equal to angle ZYW is
A. If two parallels are cut by a transverse, then alternate interior angles are congruent
What are alternate interior anglesAlternate interior angles are a pair of angles that are formed on opposite sides of a transversal line when two parallel lines are intersected by the transversal.
When a transversal intersects two parallel lines, it creates eight angles. Among these angles, the alternate interior angles are located on the inside of the parallel lines and on opposite sides of the transversal.
In a parallelogram, the two opposite sides are parallel to each other hence the line crossing them will lead to formation of alternate interior angles
Learn more about alternate interior angles at
https://brainly.com/question/20344743
#SPJ1
How many different variables are in the expression:
x3 r+xr+r+4z+6
1
2
3
4
Answers
Answer: There are three different variables.
Step-by-step explanation:
9% of all Americans live in poverty. If 47 Americans are randomly selected, find the probability that a. Exactly 5 of them live in poverty. b. At most 2 of them live in poverty. c. At least 2 of them
Answers
A. The probability that exactly 5 people live in poverty is 0.172
B. The probability that at most 2 live in poverty is 0.193
C. The probability that At least 2 of them live in poverty 0.933
How do we calculate each probabilities?This is a problem of binomial distribution. Here, each American can either live in poverty or not, which are two mutually exclusive outcomes.
We know that:
the probability of success (living in poverty), p = 0.09 (9%)
the number of trials, n = 47
a) Exactly 5 of them live in poverty.
For exactly k successes (k=5), we use the formula for binomial distribution:
P(X=k) =\(C(n, k) * p^k *(1-p)^{(n-k)}\)
it becomes
(47 choose 5)× (0.09)⁵ × (1- 0.09)⁽⁴⁷⁻⁵⁾
= 0.172
b. At most 2 of them live in poverty
For "at most k" problems, we need to find the sum of probabilities for 0, 1, and 2 successes:
P(X<=2) = P(X=0) + P(X=1) + P(X=2)
(47choose 0) × (0.09)⁰ × (0.91)⁴⁷ = 0.01188352923
+
(47 choose 1) × (0.09)¹ × (0.91)⁴⁶ = 0.05523882272
+
(47 choose 2) × (0.09)² × (0.91)⁴⁵ = 0.1256531462
therefore 0.01188352923 + 0.05523882272 + 0.1256531462 = 0.19277549815
c) At least 2 of them live in poverty.
For "at least k" problems, it's often easier to use the complement rule, which states that P(A') = 1 - P(A), where A' is the complement of A.
P(X>=2) = 1 - P(X<2) = 1 - [P(X=0) + P(X=1)]
= 1 -((47choose 0) × (0.09)⁰ × (0.91)⁴⁷ + (47 choose 1) × (0.09)¹ × (0.91)⁴⁶)
= 1 - ( 0.01188352923 + 0.05523882272)
= 1 - 0.06712235195
= 0.93287764805
Find more exercises on probability;
https://brainly.com/question/14210034
#SPJ1
f(x) = x2. What is g(x)?

Answers
Answer:
its C. yw
Step-by-step explanation:
Answer:
c
Step-by-step explanation:
i did the test
Find values of x and y for which ABCD must be a parallelogram. The diagram is not to
scale.

Answers
Step-by-step explanation:
again option D x = 10, y= 3
is the correct answer of this question.
plz mark my answer as brainlist.if you find it useful.
hope this will be helpful to you.
Answer:
x = 10
y = 7
Step-by-step explanation:
4x-2 = x+28
4x-x = 28+2
3x = 30
x = 30÷3
x = 10
4y-7 = y+14
4y-y = 14+7
3y = 21
y = 21÷3
y = 7
Which of the following statements regarding confidence intervals is FALSE? a) confidence intervals are misused more often than significance tests b) confidence intervals can be used in hypothesis testingc) confidence intervals emphasize numerical estimatesd) confidence intervals are sometimes reported in research articles
Answers
The false statement regarding confidence intervals is: a) confidence intervals are misused more often than significance tests.
Confidence intervals are statistical tools used to estimate an unknown population parameter based on a sample. They provide a range of values within which the true population parameter is likely to fall with a certain level of confidence.
Option a) states that confidence intervals are misused more often than significance tests. This statement is false. While it is true that both confidence intervals and significance tests can be misused if not understood or applied correctly, there is no evidence to suggest that confidence intervals are misused more frequently than significance tests.
Option b) is true. Confidence intervals can indeed be used in hypothesis testing. By comparing the confidence interval to a hypothesized value or another confidence interval, one can assess whether the null hypothesis is supported or rejected.
Option c) is true. Confidence intervals do emphasize numerical estimates by providing a range of values rather than a single point estimate. They give a sense of the precision and uncertainty associated with the estimate.
Option d) is true. Confidence intervals are commonly reported in research articles, particularly in fields such as statistics, social sciences, and healthcare. They provide valuable information about the precision and reliability of study findings.
In summary, the false statement is a) confidence intervals are misused more often than significance tests.
To know more about confidence intervals refer here:
https://brainly.com/question/32546207
#SPJ11
In 2020, a total of 9559 Nissan Leafs were sold in the US. For the 12-month period starting January 2020 and ending December 2020, the detailed sales numbers are as follows: 651, 808, 514, 174, 435, 426, 687, 582, 662, 1551, 1295 and 1774 units.
before the Nissan plant in Smyrna, Tennessee, started to produce the Nissan Leaf they were imported from Japan. Although cars are now assembled in the US, some components still imported from Japan. Assume that the lead time from Japan is one weeks for shipping. Recall that the critical electrode material is imported from Japan. Each battery pack consists of 48 modules and each module contains four cells, for a total of 192 cells. Assume that each "unit" (= the amount required for an individual cell in the battery pack) has a value of $3 and an associated carrying cost of 30%. Moreover, assume that Nissan is responsible for holding the inventory since the units are shipped from Japan. We suppose that placing an order costs $500. Assume that Nissan wants to provide a 99.9% service level for its assembly plant because any missing components will force the assembly lines to come to a halt. Use the 2020 demand observations to estimate the annual demand distribution assuming demand for Nissan Leafs is normally distributed. For simplicity, assume there are 360 days per year, 30 days per month, and 7 days per week.
(a) What is the optimal order quantity?
(b) What is the approximate time between orders?
Answers
(a)The optimal order quantity is 4609 units.
(b)The time between orders is 1.98 months.
To determine the optimal order quantity and the approximate time between orders, the Economic Order Quantity (EOQ) model. The EOQ model minimizes the total cost of inventory by balancing ordering costs and carrying costs.
Optimal Order Quantity:
The formula for the EOQ is given by:
EOQ = √[(2DS) / H]
Where:
D = Annual demand
S = Cost per order
H = Holding cost per unit per year
calculate the annual demand (D) using the 2020
sales numbers provided:
D = 651 + 808 + 514 + 174 + 435 + 426 + 687 + 582 + 662 + 1551 + 1295 + 1774
= 9559 units
To calculate the cost per order (S) and the holding cost per unit per year (H).
The cost per order (S) is given as $500.
The holding cost per unit per year (H) calculated as follows:
H = Carrying cost percentage × Unit value
= 0.30 × $3
= $0.90
substitute these values into the EOQ formula:
EOQ = √[(2 × 9559 × $500) / $0.90]
= √[19118000 / $0.90]
≈ √21242222.22
≈ 4608.71
Approximate Time Between Orders:
To calculate the approximate time between orders, we'll divide the total number of working days in a year by the number of orders per year.
Assuming 360 days in a year and a lead time of 1 week (7 days) for shipping, we have:
Working days in a year = 360 - 7 = 353 days
Approximate time between orders = Working days in a year / Number of orders per year
= 353 / (9559 / 4609)
= 0.165 years
Converting this time to months:
Approximate time between orders (months) = 0.165 × 12
= 1.98 months
To know more about quantity here
https://brainly.com/question/14581760
#SPJ4
Problem 1 Unit Conversion The density of gold is approximately p= 19.32 g/cm³: what is the density of gold in kg/m³? (5 points)
Answers
Answer:
19320 kg/m³
Step-by-step explanation:
Pre-SolvingWe are given that the density of gold is 19.32 g/cm³, and we want to convert that density to kg/m³.
We can solve this in a manner similar to dimensional analysis, which is common in chemistry. When we do dimensional analysis, we use conversion factors with labels that we cancel out in order to get to the labels that we want.
SolvingRecall that 1 kg is 1000 g, and 1 m³ is cm. These will be our conversion factors.
So, we can do the following:
\(\frac{19.32g}{1 cm^3} * \frac{1000000 cm^3}{1 m^3} * \frac{1kg}{1000g}\) = 19320 kg/m³
So, the density of gold is 19320 kg/m³.
If a public utility company is considered a monopolist, which of the following is not true? A. The company's demand curve and supply curve are upward sloping. B. Its price must be higher than its marginal revenue. C. For the company to practice price discrimination, there should not be any resale of its product. D. Its profit maximizing quantity is determined where its marginal revenue equals its marginal cost.
Answers
For the company to practice price discrimination, there should not be any resale of its product, is not true if a public utility company is considered a monopolist. This is because price discrimination involves charging different prices to different groups of customers based on their willingness to pay. Resale of the product can actually facilitate price discrimination as it allows different customers to buy the product at different prices and then resell it to others. The other options are true for a monopolist, such as having upward sloping demand and supply curves, charging a price higher than its marginal revenue, and determining profit maximizing quantity at the point where marginal revenue equals marginal cost.
Let's analyze each statement:
A. The company's demand curve and supply curve are upward sloping.
This statement is NOT true for a monopolist. A monopolist faces a downward sloping demand curve, which means that they can increase the quantity sold by lowering the price. The supply curve does not apply in the traditional sense for monopolists, as they have the power to set both the price and quantity produced.
B. Its price must be higher than its marginal revenue.
This statement is true for a monopolist. Under a monopoly, the price charged by the company is higher than its marginal revenue due to the downward-sloping demand curve.
C. For the company to practice price discrimination, there should not be any resale of its product.
This statement is true. In order for a monopolist to successfully engage in price discrimination, they must prevent the resale of their product, ensuring that consumers cannot undercut the monopolist's pricing strategy.
D. Its profit maximizing quantity is determined where its marginal revenue equals its marginal cost.
This statement is true. A monopolist maximizes its profit by producing the quantity where marginal revenue equals marginal cost, and then setting the price based on the demand curve at that quantity.
So, the statement that is NOT true for a public utility company considered as a monopolist is: A. The company's demand curve and supply curve are upward sloping.
To learn more about monopolist : brainly.com/question/29763908
#SPJ11
Multiply.
Answer as a fraction. Do not include spaces in your answer.
Answers
Answer:
Multiply what?
Step-by-step explanation:
Lighthouse height 8 cm scale 1 cm=4m
Answers
Answer:
8cm = 32m
Step-by-step explanation:
The answer is 32 because 8 multiplied by 4 is 32.
8 * 4 = 32.
Hope this helps! :)
please answer thanks xoxo will mark brainliest

Answers
Answer:
22) 20000000
23) 0.034
24) 0.0000000015
25) 59000000000
26) 0.0048
27) 625000
Step-by-step explanation:
susie has a bag of marbles containing 3 red, 7 green, and 10 blue marbles. in this problem, the phrase with replacement means that marbles are drawn one at a time and after the draw it is replaced back into the bag before picking the next marble. the phrase without replacement means that each marble is drawn and held onto until all marbles are drawn. 1. what is the probability of picking 5 marbles and getting at least one red marble? calculate the probability (a) with replacement, and (b) without replacement. 2. pick 8 marbles: 4 green and 4 blue. calculate the probability (a) with replacement and (b) without replacement. 3. if susie sells you 7 marbles chosen randomly without replacement, what are your chances of getting at least six marbles of the same color?
Answers
Susie needs to select minimum 14 to be sure to get 6 marbles of the same color.
With replacement
(3R, 7G, 10B)
P(at least 1 red marble) = 1- p(no red marbles) = 0.5563
P(2R, 2G, 2B) = 0.0827
P(4B, 4G) = 0.0657
Without replacement
P(at least 1 red marble) = 1- p(no red marbles) = 0.6009
P(2R, 2G, 2B) = 0.0731
P(4B, 4G) = 0.0583
if we select 3+5+5=13 marbles then there is only one way that we won't have at least 6 marbles of the same color when 3R, 5G and 5B are selected, so to get 6 marbles of the same color, we need to select minimum 14, then we will be 100% sure.
To learn more about probability, click here:
brainly.com/question/30034780
#SPJ4
16x^3
And divide
10x^1
Answers
Answer:
8x^3/5
Step-by-step explanation:
Evaluate the exponent
16x^3/10
Factor 2 out of 16x^3
2(8x^3)/10
Cancel the common factors
Factor 2 out of 10
2(8x^3)/2(5)
Cancel the common factor
(8x^3)/5
Rewrite the expression
8x^3/5
I hope this helps! :)
you are driving on a highway which indicates a maximum speed of 65 mph. but most trafficers drive at 75 mph, you should not drive faster than:
Answers
You should not drive faster than the indicated speed limit of 65 mph.
The top speed restriction on most highways is 65 mph. You may drive at 75 mph only if the posted speed limit is 75 mph. Otherwise, you should stay at your speed of 65 mph.
On the other hand, if the average speed of the traffic is 75 mph and you insist on going 65 mph. Then, instead of "moving with the flow," you become an obstruction in the road and put other drivers at graver risk.
A large number of vehicles are approaching you at 10 mph or more. A rear-end collision that may involve numerous cars might happen in the span of a split second of inattention.
The letter of the law and common sense are two different things. If you feel uneasy keeping up with the pace of the traffic. Take a different path.
To learn more about the Speed limits, visit: https://brainly.com/question/29632218
#SPJ4
.1. The Fibonacci sequence is given recursively by Fo= 0, F₁ = 1, Fn = Fn-1 + Fn-2. a. Find the first 10 terms of the Fibonacci sequence. b. Find a recursive form for the sequence 2,4,6,10,16,26,42,... C. Find a recursive form for the sequence 5,6,11,17,28,45,73,... d. Find the initial terms of the recursive sequence ...,0,0,0,0,... where the recursive formula is ZnZn-1 + Zn-2. The moral of the story is that the initial values make a BIG difference to the sequence. Don't forget to give the initial values when defining a sequence recursively!
Answers
The Fibonacci sequence is a famous sequence of numbers that starts with 0 and 1, and each subsequent term is the sum of the two preceding terms. In part (a), the first 10 terms of the Fibonacci sequence are calculated. In part (b), a recursive form for a given sequence is determined. In part (c), a recursive form for another given sequence is found. In part (d), the initial terms of a recursive sequence with a specific recursive formula are identified.
(a) To find the first 10 terms of the Fibonacci sequence, we start with 0 and 1, and then repeatedly sum the last two terms to obtain the next term. The sequence is: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34.
(b) For the sequence 2, 4, 6, 10, 16, 26, 42,..., we can observe that each term is the sum of the two preceding terms. Therefore, the recursive form for this sequence is Fn = Fn-1 + Fn-2, where F0 = 2 and F1 = 4.
(c) For the sequence 5, 6, 11, 17, 28, 45, 73,..., we can also notice that each term is the sum of the two previous terms. Thus, the recursive form for this sequence is Fn = Fn-1 + Fn-2, with F0 = 5 and F1 = 6.
(d) In the recursive sequence ...,0,0,0,0,..., the recursive formula Zn = Zn-1 + Zn-2 is given. From the given sequence, we can infer that the initial terms are Z0 = 0 and Z1 = 0.
The moral of the story is that the initial values of a recursively defined sequence significantly impact the sequence's values and behavior. In each case, providing different initial values leads to different sequences.
Learn more about Fibonacci sequence here: brainly.com/question/29764204
#SPJ11
a student researcher is comparing the wait times between two different dining facilities at ucsb. they found the 95% confidence interval for the difference in mean wait time (in minutes) between facility a and b to be [.32,1.47]. what is the most accurate interpretation of this confidence interval?
Answers
It could be slightly lower or higher, but we can be confident that it falls somewhere between 0.32 minutes and 1.47 minutes.
The most accurate interpretation of the given confidence interval is as follows:
We are 95% confident that the true difference in mean wait time between Facility A and Facility B falls within the range of 0.32 minutes to 1.47 minutes.
This means that if we were to repeat the study multiple times and calculate a new confidence interval each time, we would expect that approximately 95% of those intervals would contain the true difference in mean wait time between the two facilities.
Furthermore, based on the observed data and the calculated confidence interval, we can conclude that the difference in mean wait time between Facility A and Facility B is likely to be positive, with Facility B having a higher mean wait time than Facility A. However, we cannot say with certainty that the true difference is exactly within this specific range; it could be slightly lower or higher, but we can be confident that it falls somewhere between 0.32 minutes and 1.47 minutes.
To know more about confidence interval visit:
https://brainly.com/question/32546207
#SPJ11
30. Felipe va a hacer un banderín para su equipo de fútbol, con las medidas que se indican en la figura. ¿Cuánta tela ocupará para elaborar el banderín?
A) 930 cm2
B) 961 cm2
C) 1 860 cm2
D) 1 922 cm2
Answers
Veremos que el area del banderín es 930cm^2, entonces la opción correcta es A.
¿Que area tiene el banderin?Luego de una pequeña busqueda online, pude ver que el banderin es un triangulo isósceles con base de 31cm y altura de 60 cm.
Recordar que para un triangulo de base b y altura h, el area es:
A = b*h/2
Entonces el area del banderín va a ser:
A = (31cm)*(60cm)/2 = 930cm^2
Entonces la opción correcta es A.
Sí quieres aprender más sobre triangulos, puedes leer:
https://brainly.com/question/2217700
What is the slope-intercept form of the linear equation 4x + 2y = 24?
Answers
Answer:
y = -2x + 12
Step-by-step explanation:
Slope-intercept form
\(y=mx+b\)
where:
m is the slope.b is the y-intercept.Therefore, to find the slope-intercept form of the given linear equation, isolate y:
\(\implies 4x+2y=24\)
\(\implies 4x+2y-4x=-4x+24\)
\(\implies 2y=-4x+24\)
\(\implies \dfrac{2y}{2}=\dfrac{-4x}{2}+\dfrac{24}{2}\)
\(\implies y=-2x+12\)
Answer:
y = -2x + 12
Step-by-step explanation:
Given equation,
→ 4x + 2y = 24
The slope-intercept form is,
→ y = mx + b
Converting into slope-intercept form,
→ 4x + 2y = 24
→ 2y = -4x + 24
→ y = (-4x + 24)/2
→ [ y = -2x + 12 ]
Hence, the solution is y = -2x + 12.
In June, Clarissa used 1 gigabytes of data on her cell phone. Given that June has 30 days, how much data did she use on average per day?
Answers
Answer: 33.33 megabytes per day
Step-by-step explanation:
From the question, we are informed that in June, Clarissa used 1 gigabytes of data on her cell phone. Since June has 30 days, the amount of data she uses on average per day? will be:
= 1000megabyte/30
= 33.33mb
Note that:
1000 megabytes = 1 gigabyte
Stacey bought a bottle of water for $2.50. She also bought some hotdogs for $2.75 each at a football game. Stacey did not spend more than $12 on the hotdogs and bottle of water. Which inequality can be used to find h, the number of hotdogs that Stacey could have bought? A. 2.75x + 2.50 ≥ 12 B. 2.75x – 2.50 ≤ 12 C. 2.75x + 2.50 ≤ 12 D. 2.75x – 2.50 ≥ 12
Answers
Answer:
C. 2.75x + 2.50 ≤ 12
Explanation:
The cost of 1 hotdog = $2.75
Therefore, the cost of x hotdogs = $2.75x
Stacey also bought a bottle of water for $2.50.
Thus, the total amount Stacey spent will be:
\(2.75x+2.50\)Since she did not spend more than $12, it means:
She spent less than or exactly $12.
Thus, the inequality is:
\(2.75x+2.50\le12\)The correct choice is C.
Including an irrelevant explanatory variable in a multivariate linear regression will generally cause OLS estimators to be biased. True or false
Answers
True. Including an irrelevant explanatory variable in a multivariate linear regression can lead to biased Ordinary Least Squares (OLS) estimators.
When an irrelevant explanatory variable is included in a multivariate linear regression model, it means that the variable has no true relationship with the dependent variable. However, it can still introduce bias in the estimation process.
OLS estimators aim to minimize the sum of squared residuals by finding the coefficients that best fit the data. Including an irrelevant variable can affect the estimation process because it introduces additional noise and variation into the model. As a result, the coefficients of the relevant variables may be biased due to the presence of the irrelevant variable.
Including an irrelevant explanatory variable can lead to several issues. Firstly, it can cause overfitting, where the model fits the noise in the data rather than the underlying relationship. This leads to coefficients that are overly sensitive to the specific sample used for estimation, making them less reliable for generalizing to new data.
Additionally, the presence of an irrelevant variable violates the assumption of no multicollinearity. Multicollinearity occurs when two or more variables in the model are highly correlated. In the presence of multicollinearity, the OLS estimators become unstable and their interpretation becomes difficult.
The coefficients may be inflated or flipped in sign, further contributing to biased estimates. To avoid these biases, it is crucial to carefully select and include only relevant variables in a multivariate linear regression model.
This ensures that the estimated coefficients are unbiased and provide meaningful insights into the relationships between the explanatory variables and the dependent variable.
Learn more about variables here:
https://brainly.com/question/29583350
#SPJ11
is it possible to choose (2n 1)^2 points in the disc of radius n such that the distance between any two of them is greater than 1?
Answers
Answer: its (4f 5) ^3
Step-by-step explanation:
the actual answer pleaseee hellpp asapp

Answers
Answer:
∠BEC is supplementary to ∠AEB
∠AED and ∠BEC are a pair of vertical angles
Listed below are the results of 16 independent trials that attempted to measure quantity Q. Calculate the average value and give an uncertainty range where you can be 95% sure that the true value of Q lies within.41.31440.08741.24840.19640.28441.15238.85236.40137.94139.22139.03538.40440.68341.56842.17542.319calculate the absolute value of the difference in the two estimates of q with an uncertainty range at a 95onfidence interval. make sure you do all calculations with unrounded values.
Answers
Note that the absolute value of the difference in the two estimates of Q with an uncertainty range at a 95% confidence interval is 1.052.
What is the rationale for the above response?To find the average value of Q, we simply add up all the values and divide by the number of trials:
Average value of Q = (41.314 + 40.087 + 41.248 + 40.196 + 40.284 + 41.152 + 38.852 + 36.401 + 37.941 + 39.221 + 39.035 + 38.404 + 40.683 + 41.568 + 42.175 + 42.319)/16
= 39.976
Next, to find the uncertainty range where we can be 95% sure that the true value of Q lies within, we need to find the standard error of the mean. The formula gives this:
Standard error of the mean = standard deviation / √(n)
where n is the number of trials. We can find the standard deviation using the formula:
Standard deviation = √(Σ(Qi - Q_avg)² / (n-1))
where Qi is the value of Q for the ith trial.
Using these formulas, we find:
Standard deviation = 1.549
Standard error of the mean = 0.387
To find the uncertainty range, we say:
Uncertainty range = t-value * standard error of the mean
= 2.131 * 0.387
= 0.826
Therefore, we can be 95% sure that the true value of Q lies within the range:
39.976 ± 0.826
Now, to calculate the absolute value of the difference in the two estimates of Q with an uncertainty range at a 95% confidence interval, we can simply add the uncertainty ranges of the two estimates and take the absolute value of the difference:
|Q1 - Q2| = |39.976 ± 0.826 - 40| + |39.976 ± 0.826 - 39.8|
= 0.826 + 0.226
= 1.052
Therefore, the absolute value of the difference in the two estimates of Q with an uncertainty range at a 95% confidence interval is 1.052.
Learn more about Absolute Value at:
https://brainly.com/question/1301718
#SPJ1
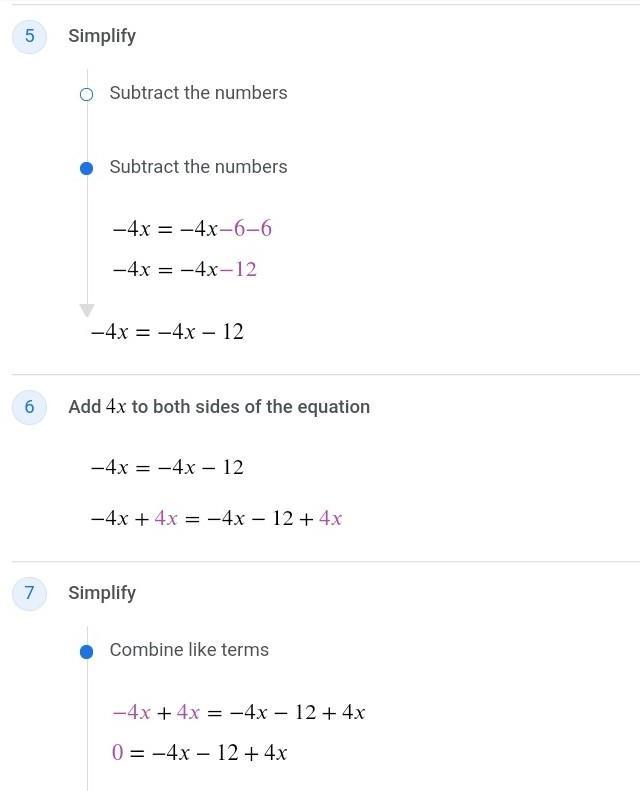
2(-2x+3)=-4(x+1)-2 solving equations
Answers
Answer:
Please click above answer.
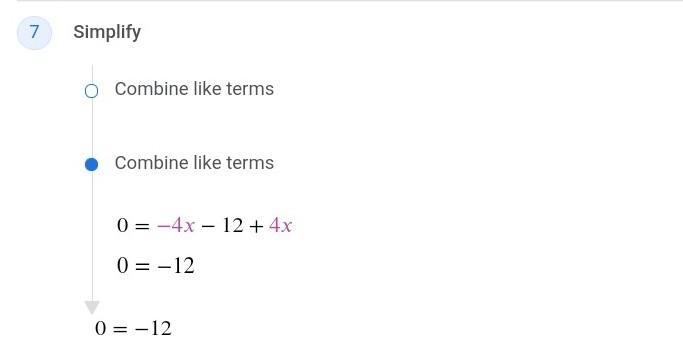
Which is the domain of y=arctan(x)
Answers
Answer:
D. All real numbers
Step-by-step explanation: